The network is slow: Part 1
Let me start off by agreeing that yes, the network is slow.
I’ve moved a fair amount of data over the years. Even when it’s only a terabyte or two, the network always seems uncomfortably slow. We never seem to get the performance we sketched out on the whiteboard, so the data transfer takes way longer than expected. The conversation quickly turns to the question of blame, and the blame falls on the network.
No disagreement there. Allow me to repeat: Yes, the network is slow.
This post is the first in a series where I will share a few simple tools and techniques to unpack and quantify that slowness and get things moving. Sometimes, hear me out, it’s not the entire network that’s slow – it’s that damn USB disk you have plugged into your laptop, connected over the guest wi-fi at Panera, and sprayed across half a continent by a helpful corporate VPN.
True story.
My point here is not to show you one crazy old trick that will let you move petabytes at line-rate. Rather, I’m hoping to inspire curiosity. Slow networks are made out of fast and slow pieces. If you can identify and remove the slowest link, that slow connection might spring to life.
This post is about old-school, low-level Unix/Linux admin stuff. There is nothing new or novel here. In fact, I’m sure that it’s been written a bunch of times before. I have tried to strike a balance to make an accessible read for the average command line user, while acknowledging a few of the more subtle complexities for the pros in the audience.
Spoiler alert: I’m not even going to get to the network in this post. This first one is entirely consumed with slinging data around inside my laptop.
Endless zeroes
When you get deep enough into the guts of Linux, everything winds up looking like a file. Wander into directories like /dev or /proc, and you will find files that have some truly weird and wonderful properties. The two special files I’m interested in today both live in the directory /dev. They are named “null” and “zero”.
/dev/null is the garbage disposal of Linux. It silently absorbs whatever is written to it, and never gives anything back. You can’t even read from it!
energon:~ cdwan$ echo "hello world" > /dev/null
energon:~ cdwan$ more /dev/null
/dev/null is not a regular file (use -f to see it)
/dev/zero is the opposite. It emits an endless stream of binary zeroes. It screams endlessly, but only when you are listening.
If you want your computer to spin its wheels for a bit, you can connect the two files together like this:
energon:~ cdwan$ cat /dev/zero > /dev/null
This does a whole lot of nothing, creating and throwing away zeroes just as fast as one of the processors on my laptop can do it. Below, you can see that my “cat” process is taking up 99.7% of a CPU – which makes it the busiest thing on my system this morning.
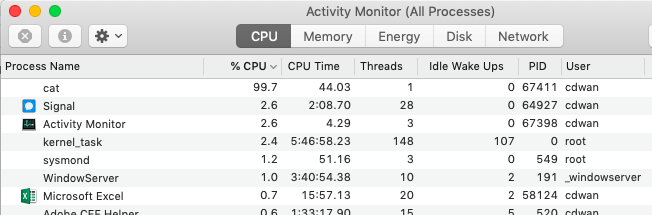
Which, for me, raises the question: How fast am I throwing away data?
Writing nothing to nowhere
If my laptop, or any other Linux machine, is going to be involved in a data transfer, then the maximum rate at which I can pass data across the CPU matters a lot. My ‘cat’ process above looks pretty efficient from the outside, with that 99.7% CPU utilization, but I find myself curious to know exactly how fast that useless, repetitive data is flowing down the drain.
For this we need to introduce a very old tool indeed: ‘dd’.
When I was an undergraduate, I worked with a team in university IT responsible for data backups. We used dd, along with a few other low level tools, to write byte-level images of disks to tape. dd is a simple tool – it takes data from an input (specified with “if=”) and sends it to an output (specified with “of=”).
The command below reads data from /dev/zero and sends it to /dev/null, just like my “cat” example above. I’ve set it up to write a little over a million 1kb blocks, which works out to exactly a gigabyte of zeroes. On my laptop, that takes about 2 seconds, for a throughput of something like half a GB/sec.
energon:~ cdwan$ dd if=/dev/zero of=/dev/null bs=1024 count=1048576
1073741824 bytes transferred in 2.135181 secs (502880950 bytes/sec)
The same command, run on the cloud server hosting this website, finishes in a little under one second.
[ec2-user@ip-172-30-1-114 ~]$ dd if=/dev/zero of=/dev/null bs=1024 count=1048576
1073741824 bytes (1.1 GB) copied, 0.979381 s, 1.1 GB/s
Some of this difference can be attributed to CPU clock speed. My laptop runs at 1.8GHz, while the cloud server runs at 2.4GHz. There are also differences in the speed of the system memory. There may be interference from other tasks taking up time on each machine. Finally, the system architecture has layers of cache and acceleration tuned for various purposes.
My point here is not to optimize the velocity of wasted CPU cycles, but to inspire a bit of curiosity. While premature optimization is always a risk – I will happily take a couple of factors of two in performance by thinking through the problem ahead of time.
As an aside, you can find out tons of useful stuff about your Linux machine by poking around in the /proc directory. Look, but don’t touch.
[ec2-user@ip-172-30-1-114 ~]$ more /proc/cpuinfo | grep GHz
model name : Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz
Reading and writing files
So now we’ve got a way to measure the highest speed at which a single process on a single CPU might be able to fling data. The next step is to ask questions about actual files. Instead of throwing away all those zeroes, let’s catch them in a file instead:
energon:~ cdwan$ dd if=/dev/zero of=one_gig bs=1024 count=1048576
1073741824 bytes transferred in 7.431081 secs (144493358 bytes/sec)
energon:~ cdwan$ ls -lh one_gig
-rw-r--r-- 1 cdwan staff 1.0G Mar 5 08:57 one_gig
Notice that it took almost four times as long to write those zeroes to an actual file instead of hurling them into /dev/null.
The performance when reading the file lands right in the middle of the two measurements:
energon:~ cdwan$ dd if=one_gig of=/dev/null bs=1024 count=1048576
1073741824 bytes transferred in 4.222885 secs (254267367 bytes/sec)
At a gut level, this makes sense. It kinda-sorta ought-to take longer to write something down than to read it back. The caches involved in both reading and writing mean we may see different results if we re-run these commands over and over. Personally, I love interrogating the behavior of a system to see if I can predict and understand the way that performance changes based on my understanding of the architecture.
I know, you were hoping to just move data around at speed over this terribly slow network. Here I am prattling on about caches and CPUs and RAM and so on.
As I said above, my point here is not to provide answers but to provoke questions. Agreed that the network is slow – but perhaps there is some part of the network that is most to blame.
I keep talking about that USB disk. There’s a reason – those things are incredibly slow: Here are the numbers for reading that same 1GB file from a thumb drive:
energon:STORE N GO cdwan$ dd if=one_gig_on_usb of=/dev/null bs=1024 count=1048576
1073741824 bytes transferred in 75.596891 secs (14203518 bytes/sec)
That’s enough for one post. In the next installment, I will show a few examples of one of my all time favorite tools: iperf.